Vision Transformer ...1
This covers the idea behind building Pali Gemma Model from scratch in Python. I learnt a lot along the process, some of the key concepts around Rotary Embeddings, KVCache, etc. Big thanks to Umair Jamil's youtube, without which I'd be rendered with much less help!
If you're new to this, well don't worry, I'm here to help :)
Assuming that you have a basic understanding of Transformer model; a Vision transformer is just a Transformer with images. Use cases revolve around object segmentation, object detection. Consider your gf sends you her image, and you're a schizophrenic like me, you'll pay attention to each and every detail very attentively. Now when a computer wants to do that, it can use Vision Transformers. They outperform CNNs in computation & accuracy by a margin larger than the Wall of China.
So, a Vision language model is something that learns from both images and texts, instead of only texts as in normal Transformers. Let's start from the basic structure.
So PaliGemma has 2 parts:
- SigLip Vision Encoder
- Gemma Text Encoder
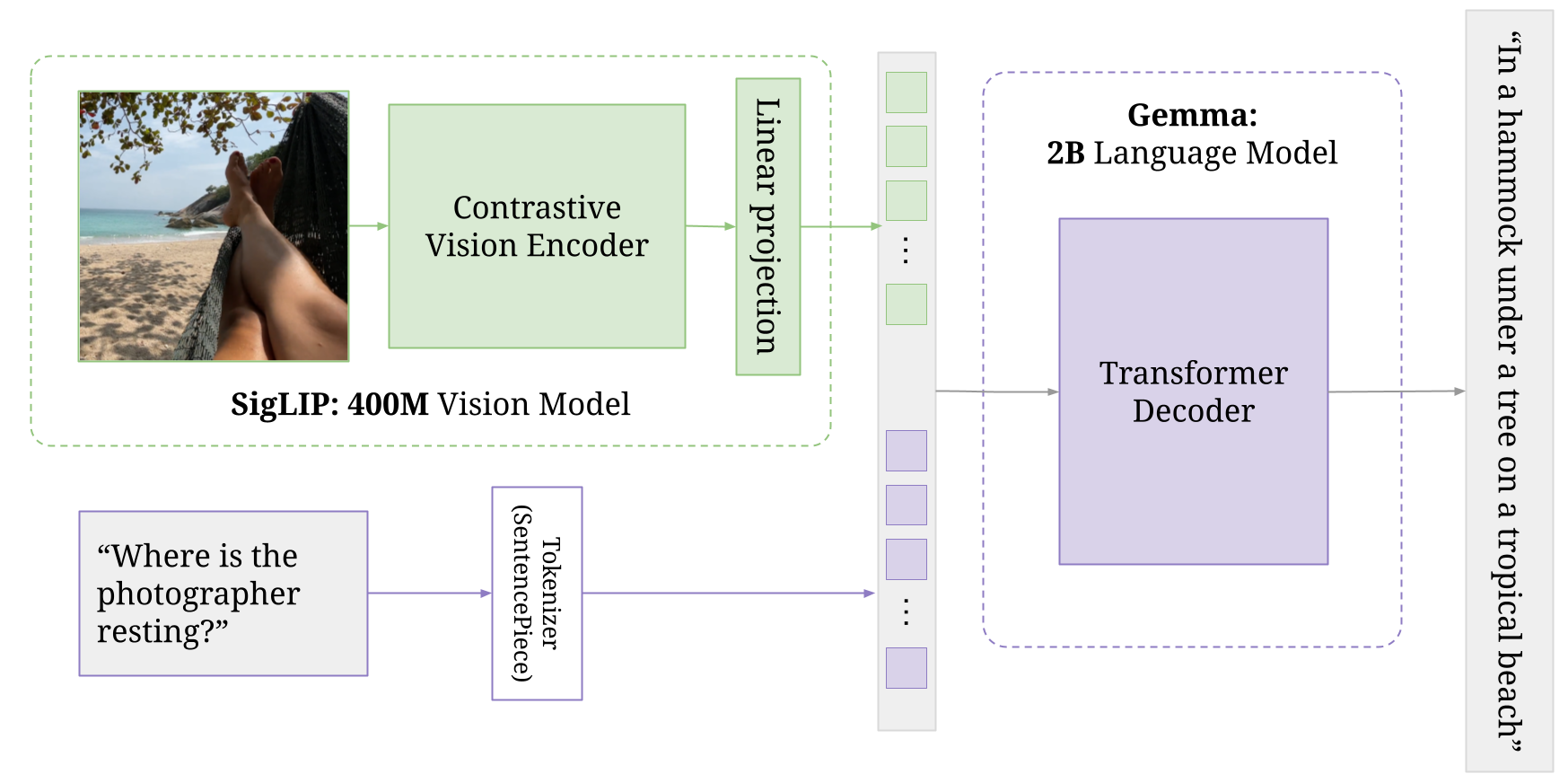 Here we'll be only covering the SigLip Vision Encoder as we have coded it.
Here we'll be only covering the SigLip Vision Encoder as we have coded it.
It consists of multiple different chunks tied together. We frist convert the images to input embeddings. Let's go one by one:
- SigLipVisionEmbeddings:
This is used to convert the image pixels to vector embeddings of suitable size and return them. A forward function does the job. Note that a forward function is always defined in some classes to help execute the code.
def forward(self, pixel_values:torch.FloatTensor) -> torch.Tensor:
_, _, height, width = pixel_values.shape
patch_embeds = self.patch_embedding(pixel_values)
embeddings = patch_embeds.flatten(2) #
embeddings = embeddings.transpose(1,2)
# attach positional encoding to flattened layer
embeddings = embeddings + self.position_embedding(self.position_ids)
return embeddings
- Attention:
As you're aware, attention is the single most important block in any transformer model as it helps in paying "attention" to certain segments of an imager (here) that are more important than others in the provided prompts.
 What we're doing here, is
What we're doing here, is - taking the transpose of k (key_state) == kT
- multiply it with q (query_state)
- dividing it by square root of dk == dimensions of value_state
- softmaxing it
- multiplying it by v (value_state)
This gives us the attention values of every embedding.
We define the basic elements of attention as:
query_states = self.q_proj(hidden_states)
key_states = self.k_proj(hidden_states)
value_states = self.v_proj(hidden_states)
- SigLipEncoderLayer: This layer is used to mask and encode the vector embeddings of the image. It consists of an attention sequence of itself and a feed forward network to make it work (generally a Multi Layered Perceptron - MLP). This helps capture the relationship between different segments of the image and compress it to useful-only encodings of a fixed size.
self.embed_dim = config.hidden_size
self.self_attn = SigLipAttention(config) # self attention
self.layer_norm1 = nn.LayerNorm(...)
self.mlp = SigLipMLP(config) # multi layer perceptron
self.layer_norm2 = nn.LayerNorm(...)
- Finally, we have an output class
SiglipVisionTransformerthat combines the processing of the previous classes and produces an output in the form of embeddings
This covers our first part of scrolling through Pali Gemma.
There's More...
This was the first of 'n' parts of a series I'm writing that covers the basics about Vision Language models, considering Pali Gemma as a reference. So, watch out :)